清华大学研发 LLM4VG 基准:用于评估 LLM 视频时序定位性能
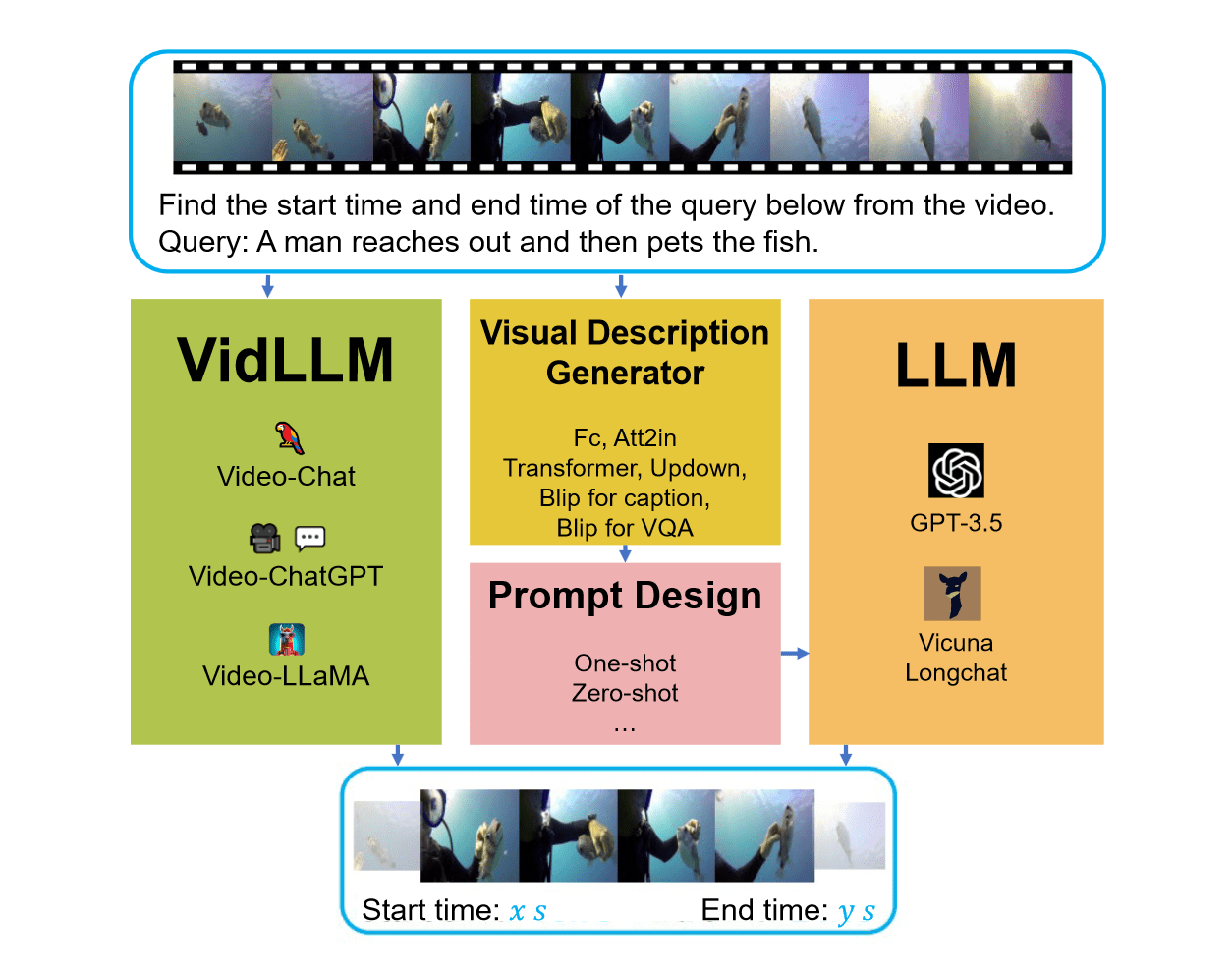
VG 任务的目的基于给定查询(一句描述),然后在目标视频段中定位起始和结束时间,核心挑战在于时间边界定位的精度。
清华大学研究团队近日推出了“LLM4VG”基准,这是一个专门设计用于评估 LLM 在 VG 任务中的性能。
此基准考虑了两种主要策略:第一种涉及直接在文本视频数据集(VidLLM)上训练的视频 LLM,第二种是结合传统的 LLM 与预训练的视觉模型。
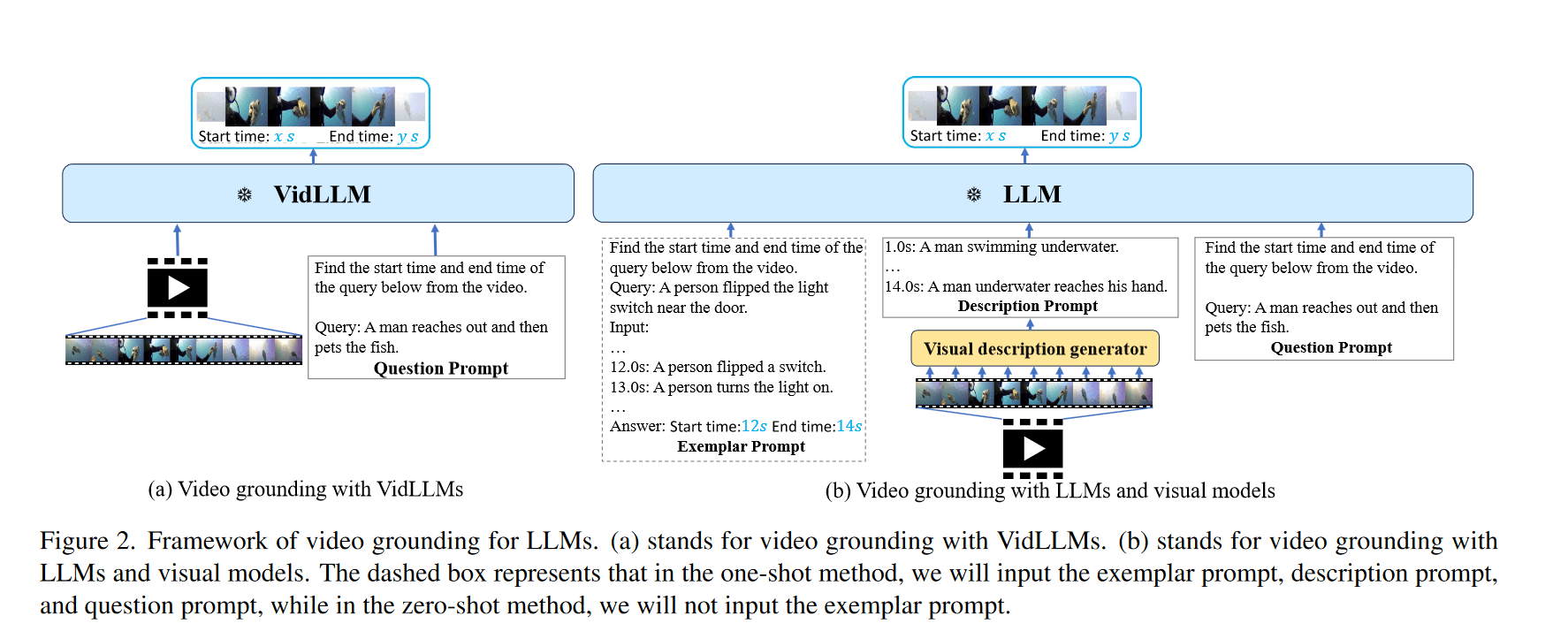
在第一种策略中,VidLLM 直接处理视频内容和 VG 任务指令,根据其对文本-视频的训练输出预测。
第二种策略更为复杂,涉及 LLM 和视觉描述模型。这些模型生成与 VG 任务指令集成的视频内容的文本描述,通过精心设计的提示。
这些提示经过专门设计,可以有效地将 VG 的指令与给定的视觉描述结合起来,从而让 LLM 能够处理和理解有关任务的视频内容。
据观察,VidLLM 尽管直接在视频内容上进行训练,但在实现令人满意的 VG 性能方面仍然存在很大差距。这一发现强调了在训练中纳入更多与时间相关的视频任务以提高性能的必要性。

而第二种策略优于 VidLLM,为未来的研究指明了一个有希望的方向。该策略主要限制于视觉模型的局限性和提示词的设计,因此能够生成详细且准确的视频描述后,更精细的图形模型可以大幅提高 LLM 的 VG 性能。
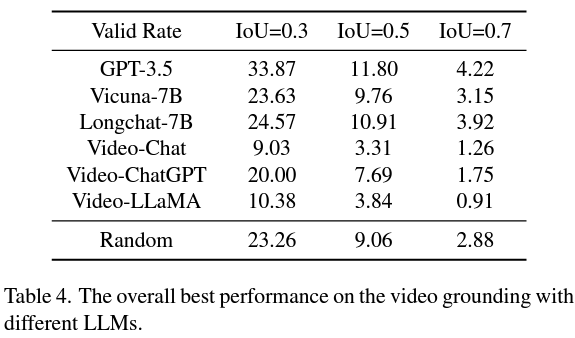
总之,该研究对 LLM 在 VG 任务中的应用进行了开创性的评估,强调了在模型训练和提示设计中需要更复杂的方法。
IT之家附上论文参考地址:https://arxiv.org/pdf/2312.14206.pdf
免责声明:以上内容(如有图片或视频亦包括在内)为本站用户上传并发布,本站仅提供信息存储服务。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,如有侵权违规信息请联系删除。






